
1. はじめに
スマホやカーナビが自然にしゃべるのは当たり前。でも、その「当たり前」は世界の言語すべてには届いていません。話者が多い言語は高品質な音声合成(TTS)が整っている一方で、学習データが集めにくい言語(低リソース言語)では、いまだに不自然な発音・抑揚・聞き取りにくさが残ります。
この格差を埋める技術トレンドが、多言語TTS(Multilingual TTS)と、そこから派生するクロス言語のボイスクローン(Cross-language voice cloning)です。研究面では「多言語をまとめて学習して共有する」発想が進み、特許面では「話者らしさと言語らしさを分離する」「データ不足を前提に学習を成立させる」設計が増えています。
2. 多言語TTSが変える世界(メインテーマ)
2-1. そもそもTTSは「文字→声」ではなく「文字→設計図→音」
現代のTTSは、だいたい次の2段階です。
(1) テキストから「音の設計図」を作る(多くはメルスペクトログラムのような中間表現)
(2) 設計図から波形を作る(ボコーダ/ニューラルボコーダ等)
重要なのは、(1)が単なる読み上げではなく、抑揚・間・感情・話者らしさなどの“非言語情報”も同時に設計している点です。ここが多言語化・低リソース化で一気に難しくなります。言語が違えば音素体系が違い、文字体系も違い、データの量も質も揃いません。
2-2. 低リソース言語のボトルネックは「量」だけでなく「偏り」
低リソース言語では「録音が少ない」だけでなく、データの偏り(話者が少ない、収録環境が同質、文章が限定的)が起きがちです。するとモデルは、言語の一般性よりも“そのデータセットの癖”を覚えやすい。
だから最近の設計は、単純にデータを増やすよりも「多言語で表現を共有して不足を補う」「話者情報と言語情報を分離して混線を減らす」方向へ進みます。低リソースを“前提”に、学習を安定させる発想です。
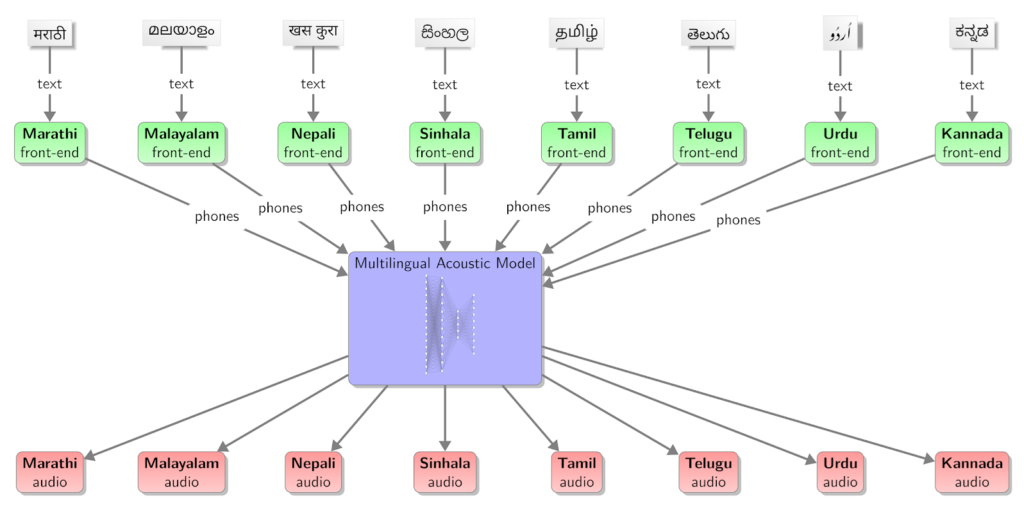
2-3. いまの主戦場は「共有」と「分離」:言語横断で“声の核”を作る
多言語TTSの設計思想を一言で言うと、共有できるところは共有し、混ざると困るものは分離する。
共有したいのは、音声生成の普遍的な能力(韻律、滑らかさ、時間伸縮、自然さ)。
分離したいのは、(a) 話者固有の特徴(声質)と、(b) 言語固有の発音規則(音素・アクセント)です。
この「共有」と「分離」を、どう“装置化”しているのか。ここからが面白いところです。
3. 特許から見る技術革新
3-1. WO2020242662A1 の解説:クロス言語ボイスクローンを“成立させる”分離設計
この特許の核は、多言語TTSとクロス言語ボイスクローンを同じ枠組みで扱いつつ、「声質」と「言語」を分けて学習しやすくする点です。ポイントは、モデル内部に話者埋め込み(speaker embedding)と言語埋め込み(language embedding)のような“区別の箱”を用意し、さらに 敵対的な学習(adversarial)の発想で、テキスト由来の表現から“話者情報が漏れにくい”方向へ寄せることです。データが少ない環境ほど「声」と「言語」が絡みやすいので、分離設計の価値が上がります。
3-2. US20230298567A1 の解説:低リソースで効く「ペアなしデータ」発想
低リソース言語の厄介さは、「テキストと音声がきれいに対応した教材」が手に入りにくいことです。この特許が示唆する方向性の一つは、“ペアになっていないデータ”も活用して性能を上げるという発想です。つまり「音声はあるが文字起こしが弱い」「テキストはあるが音声収録が少ない」といった現実に合わせて、学習を組み立てます。噛み砕けば「完璧な教科書がなくても、参考書や問題集を寄せ集めて学習を成立させる」イメージです。こうした設計が進むほど、低リソース言語への展開速度は上がります。
3-3. US20250078805A1 の解説:“スケールさせる”ための多言語学習
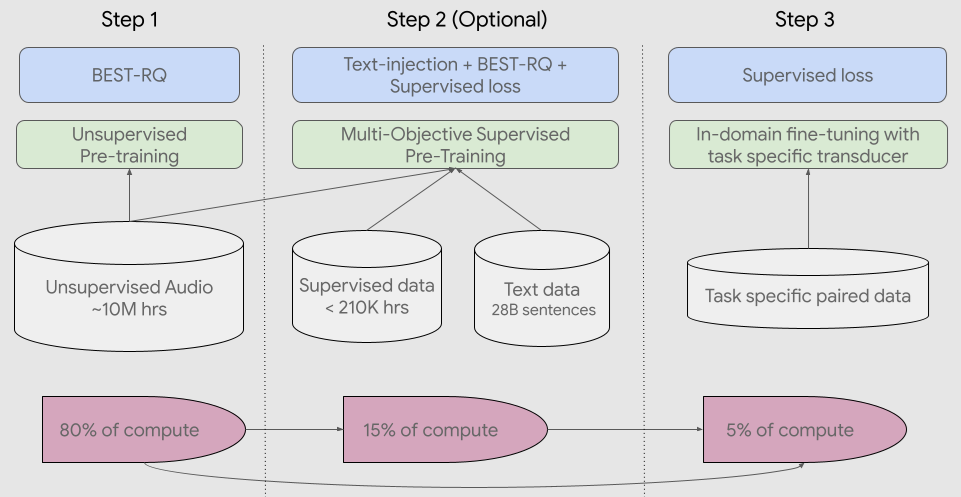
多言語TTSを社会実装レベルで考えると、最終的には「1言語ずつ職人芸で作る」のではなく、多言語を束ねてスケールさせる訓練戦略が重要になります。この特許は、まさに“スケール”側の発想を強く感じさせるタイプです。言語・話者・データの集まり方がバラバラでもモデル全体として性能が伸びるように学習の枠組みを設計していく、研究の世界では「巨大な音声基盤モデル」へ向かう流れがあります(膨大な音声とテキストで多言語性能を引き上げる)。
4. 応用分野・実用化
4-1. 多言語アシスタントの「声の均質化」:製品体験を国境の外へ
多言語TTSが成熟すると、製品の体験が「言語によって別物」になりにくくなります。読み上げ品質が揃えば、グローバルサービスは“音声UIの輸出”ができる。特に、低リソース言語のカバーが広がるほど、「特定の地域だけ音声UIが弱い」という不公平が減ります。
4-2. クロス言語ボイスクローン:吹替・ナレーション・教育が一気に変わる
クロス言語ボイスクローンが一般化すると、同一人物の声で多言語展開が可能になります。もちろん悪用リスクは後述しますが、これにより、正当な用途では「教育」「医療情報の多言語化」「災害情報のローカライズ」「アクセシビリティ」など、社会的インパクトが大きくなります。
4-3. 企業の現場:コールセンター/多言語研修/音声ドキュメント
企業側の実用化で効くのは、(1) 社内の多言語研修、(2) 多言語FAQや読み上げ、(3) 音声ドキュメント化です。つまり「多言語TTSは翻訳の延長」ではなく「情報の届け方そのものを変える技術」になります。
5. 課題と展望
5-1. 現在の課題:品質・公平性・そして「声のなりすまし」
多言語TTSが進むほど、避けられない課題は3つです。
(1) 言語ごとの品質差(低リソースほど不利)
(2) データ偏りによる公平性・バイアス
(3) ボイスクローン悪用(なりすまし、詐欺、同意なき複製)
特許は(1)(2)を“技術で解く”側に寄りがちですが、社会実装では(3)が必ずセットで問われます。だからこそ、技術を「できる/できない」だけでなく「どう設計し、どう運用するか」まで読む必要がでてきます。
5-2. 研究の最前線:ゼロショット・多話者・多言語の“統合”
研究側では、少量データで新しい話者や言語へ適応する方向(ゼロショット/少ショット)が伸びています。
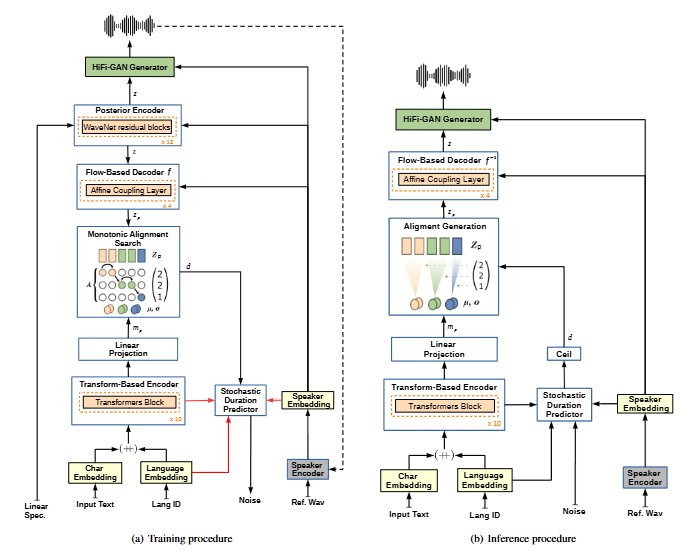
また、データセット整備も重要で、CML-TTSのように多言語TTS向けデータを用意する研究も出ています。
5-3. 未来の展望:「翻訳」より先に「声」が地球規模で揃う
近い将来、テキスト翻訳の前に「話す・聞く」体験が先に揃う可能性があります。理由はシンプルで、音声は教育・行政・生活導線に刺さりやすいためです。USMのような大規模音声モデルの潮流は、その“揃う速度”を押し上げます。
この波の中で、特許は「各社がどこをコアと見ているか」「どこで差別化するか」を覗く窓になります。多言語TTSはまさに、特許を読む価値が高いテーマです。
6. 結論
多言語TTSの核心は、「データ不足を無理やり埋める」のではなく、多言語で表現を共有し、混ざると困る要素(話者×言語)を分離して学習を成立させることにあります。
今回見た3件の特許は、それぞれ役割が違います。
- WO2020242662A1は、クロス言語ボイスクローンを含む“分離設計”の象徴
- US20230298567A1は、低リソース現実に合わせた“データの使い方”の方向性
- US20250078805A1は、産業としてスケールさせる“訓練戦略”の匂い
音声AIは、便利さの裏側でリスクも増えます。だからこそ、特許を起点に「技術の中身」と「実装上の論点」をセットで掴めると、ニュースが一段深く読めるようになります。
関連アイテム
『進化するヒトと機械の音声コミュニケーション Vol.2:AIの活用と感情に寄り添う音声認識・合成の新展開』
多言語TTSを“声のOS”として実装していく上で、音声認識(ASR)と音声合成(TTS)の全体像・応用・設計論点を体系的に押さえたい方向けの1冊。
参考文献
テーマに近い関連する特許文献
- WO2020242662A1 — Multilingual speech synthesis and cross-language voice cloning
https://patents.google.com/patent/WO2020242662A1/en - US20230298567A1 — Speech synthesis and speech recognition
https://patents.google.com/patent/US20230298567A1/en - US20250078805A1 — Scaling Multilingual Speech …
https://patents.google.com/patent/US20250078805A1/en
記事を作成するにあたり参考にした文献
- Google Research Blog: Text-to-Speech for Low-Resource Languages
https://blog.research.google/2018/09/text-to-speech-for-low-resource.html - Google Research Blog: Universal Speech Model (USM)
https://research.google/blog/universal-speech-model-usm-state-of-the-art-speech-ai-for-100-languages/ - SpringerOpen: Text-to-speech system for low-resource language using cross-lingual transfer learning and data augmentation
https://link.springer.com/article/10.1186/s13636-021-00225-4 - arXiv: YourTTS: Towards Zero-Shot Multi-Speaker TTS
https://arxiv.org/abs/2112.02418 - ACL Anthology(PDF): Low-Resource Multilingual and Zero-Shot Multispeaker TTS
https://aclanthology.org/2022.aacl-main.56.pdf - arXiv: CML-TTS: A Multilingual Dataset for Speech Synthesis
https://arxiv.org/abs/2306.10097
※ 記事は公開されている特許情報および学術研究をもとに作成しています。図版は各出典元から引用しています。
コメント